Table of contents
Prioritisation for agile development
Scenario 1: “Data-driven government” (DD-gov)
Scenario 2: “Data-driven internationalization of a business” (DD-business)
Scenario 4: “Know your international partner”
Design for Change: Evolvability
Columns or rows? For humans or machines?
National Business Registers holds data representing national terminology
Report
Introduction
This report is related to the following objective of STIRData:
Define a set of user scenarios demonstrating specific examples of how harmonised and interlinked open company-related data can offer new opportunities for their further exploitation and reuse across Member States.
Prioritisation for agile development
Identifying and analysing the datasets, and identifying and prioritising the use cases, creates the basis for the other work packages in the STIRData project, for instance the requirements to the architecture, the transformation to linked data and the platform for navigation, analysis and visualisation. To make sure we had relevant input to the other activities, the dataset and use case work was continuously adapted to meet the most important needs. Below is a description of the work and the priorities during the process.
To be able to start activities related to the architecture, specification and the implementation of the platform, it was not an option to work on these elements sequentially, completing one task before starting the next. For the implementation to start there was also a need for use cases that reflected the data that we were able to get access to. As a result, we started by identifying potential datasets in addition to the three business registers already part of the project, and which elements were available in the different sources.
The work was documented in a matrix, as a sheet in the 2.3 Dataset Analysis document. The illustration below shows an excerpt of the information elements we looked at (left column) and the status in the first five datasets, representing NO, CZ, GR, BE and FI:

When we had an adequate insight in which information elements would be available for the implementation in the project period, we made an initial analysis of which of these elements likely to be relevant for the different scenarios, before we started detailing the scenarios in use cases.
This work was documented in another matrix in the same document, 2.3 Dataset Analysis, where the information elements are listed in the left column and then there is a categorisation for each of the scenarios (Mandatory, Relevant, Not Relevant, Uncertain (?) and Not applicable (N/A)). The illustration below shows an excerpt of the matrix:
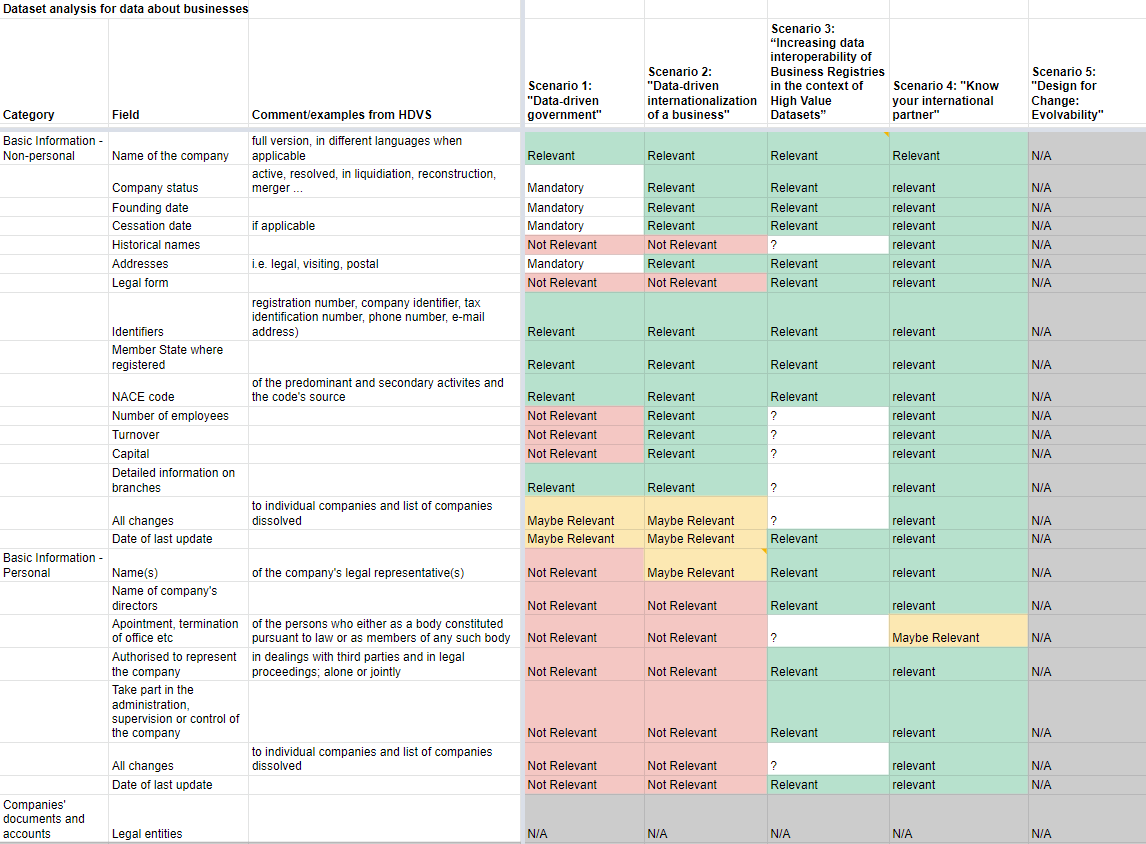
The result was a matrix that identified data elements and availability from different countries.
At this point there were enough details to also start working on converting information elements from the data sources to linked data versions of the data sets. In this phase there were more detailed questions and discussions on mapping the information elements to existing vocabularies, which led to drafting a data model to convert the data to, the STIRData business data model.
In the Datasets-part of this report all the sources that are currently used are documented, as well as the mapping of the information in the elements to the shared data model. Also, other supplementing sources for enriching the data are listed here, for instance national sources for activity codes (NACE).
With the data available, the implementation of the front end of the platform could start. This front-end mainly supports the scenarios related to navigating and analysing the data, and therefore we started by detailing these scenarios in use cases.
Before the actual implementation of the front-end there a set of proposals for designs were made, and where relevant, these were related to the use cases. During the process we had several iterations on the design proposals. As part of the feedback process, new requirements were identified and in some cases, as part of the discussion, we also discovered use cases that had been implicit by the team members.
This illustrates the risk that a team of experts share a set of implicitly understood requirements that are not then expressed explicitly, as use cases. The iterations on the proposals for the design were helpful. Also, we believe that open documentation of the identified use cases and requirements on GitHub (see below) will make it easier for external parties to add their knowledge and requirements.
When discussing the front end, we also had to take into account the limitation of what could be implemented during the course of the STIRData-project, both in terms of the resources (hours) and the data available
After the work on the implementation of the front end has started, more focus has been given to the use cases that are independent of the front end. These use cases play an important role in validating the architecture and the specifications, even if they will not necessarily be implemented.
Use cases
Background and methodology
In the application, there were already identified four high-level Scenarios.[1] These were:
- Scenario 1: “Data-driven government”
- Scenario 2: “Data-driven internationalization of a business”
- Scenario 3: “Increasing data interoperability of Business Registries in the context of High Value Datasets”
- Scenario 4: “Know your international partner”
Regarding Scenario 3, that scenario has not been detailed. We believe the intention of the scenario as it was described in the application is supported by the other four scenarios.
Early in the project, we decided to also add a fifth scenario to take into account the need for a transition over time to the end-state, as well as an end-state that has built in the capability to evolve for continuous development. We called this “Design for Change: Evolvability”
To move from the high-level use scenarios, to more specific use cases, we decided to document and analyse the scenarios using GitHub Issues and Projects. Scenarios are described in issues as an Epic, and detailed in more specific User Stories. The relationship is done both by using the labels-functionality, as well as listing the related user stories on each Epic:
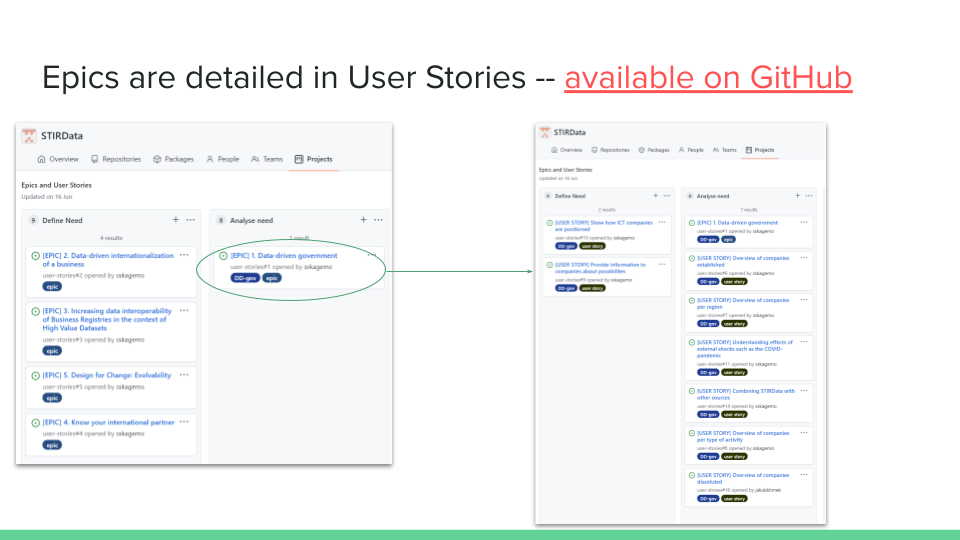
By relating all the issues – both Epics and User Stories – to a GitHub Project, we get a Kanban-board with all the issues. This is useful to see how to move the issues through different phases, from defining the need, through analysing it and describing a solution, and finally implementation and verification. An important disclaimer is that the project will identify and describe more User Stories than what is possible to implement during the project, due to limitations in time, resources and currently available data. But it is important that these User Stories are identified and documented, and used to influence the architecture and specifications, to ensure these are as well fitted for future use as possible.
Only the team-members with write access can triage and change status on the issues, but everyone with a github-user can add issues, and comment on existing issues. Using GitHub issues also ensures transparency about the discussion, prioritisation and processing of the issues.
[screenshot of Kanban Board]
Using the label-functionality, it is easy to filter the board, for instance in order to only look at issues related to a specific scenario/epic, such as DD-gov (for Data Driven Government):
[Screenshot of kanban-board with filtering for DD-gov]:
If we look at an example of a User Story, we can see how the issue includes the type User Story in the title, as well as through a label (for filtering). Furthermore it has a describing title, and a formulation of the type
“As a [role] I wish to [description of what] So that I [description of benefit]”
[Screenshot of issue #33]
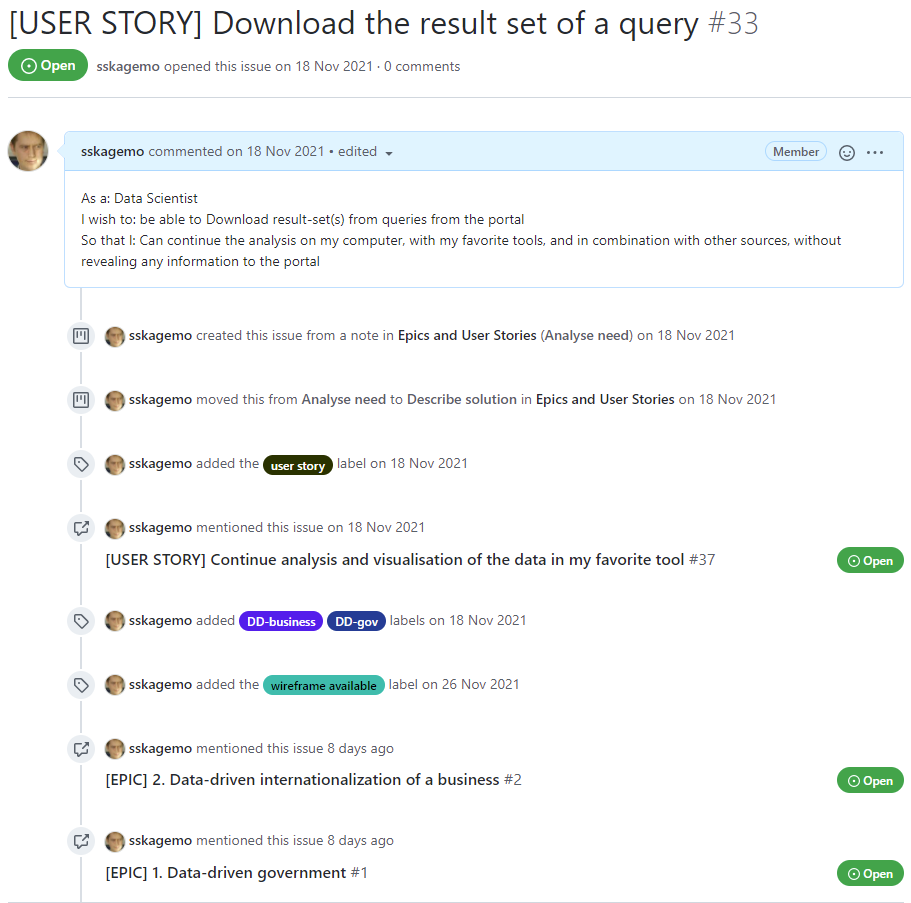
It is also visible how the issue has been processed, for instance has this issue been mentioned in another issue, the User Story about being able to continue analysis and visualisation of data in the users favourite tool, and it has been related to two different Epics, (Data-driven internationalization of a business, as well as Data-driven government), as the role of the User Story is a data scientist, that might exist both in government and private companies.
Scenarios
Below, we go through the Scenarios and the list of User Stories currently identified (March 2022). As
Scenario 1: “Data-driven government” (DD-gov)
Below is a snapshot of the Epic, from https://github.com/STIRData/user-stories/issues/1
As a: Public Administration
I wish to: retrieve and provide a comparative overview of companies which were established or went out of business over the last period of time per region and per type of activity as well as information about development in similar regions; provide information to companies about the possibilities to expand their business; show how ICT-companies compares across different regions or countries related to different levels of digital Performance
So that I: Can base policy-making and other decisions on facts (data) about the development, both within the area(s) for which I am responsible, but also to compare with other areas.
For this Scenario, as of March 2022, 17User Stories have been identified. Several of these are also relevant for Scenario 2. The individual User Stories can be accessed on Github, with the details and related discussions.
One group of the User Stories are related to the presentation facts about the “demography” of businesses, such as overview of companies established, related to time periods, companies per region, type of activity and companies dissoluted. These User Stories have an impact on how to present data in the platform, as well as how to augment and normalise information about for instance location and activity type. #6, 7, #8, #16.
There are also a few User Stories in the same group that illustrates need for more specific knowledge, such information related to ICT-companies (#10), and understanding effects of external shocks such as the COVID-pandemic (#11). Also, comparing several regions can be important in order to learn and benchmark how differences across regions affect companies (#18). Furthermore, as government often have a role in supporting entrepreneurs, they will want to be able to provide companies about business possibilities (#9).
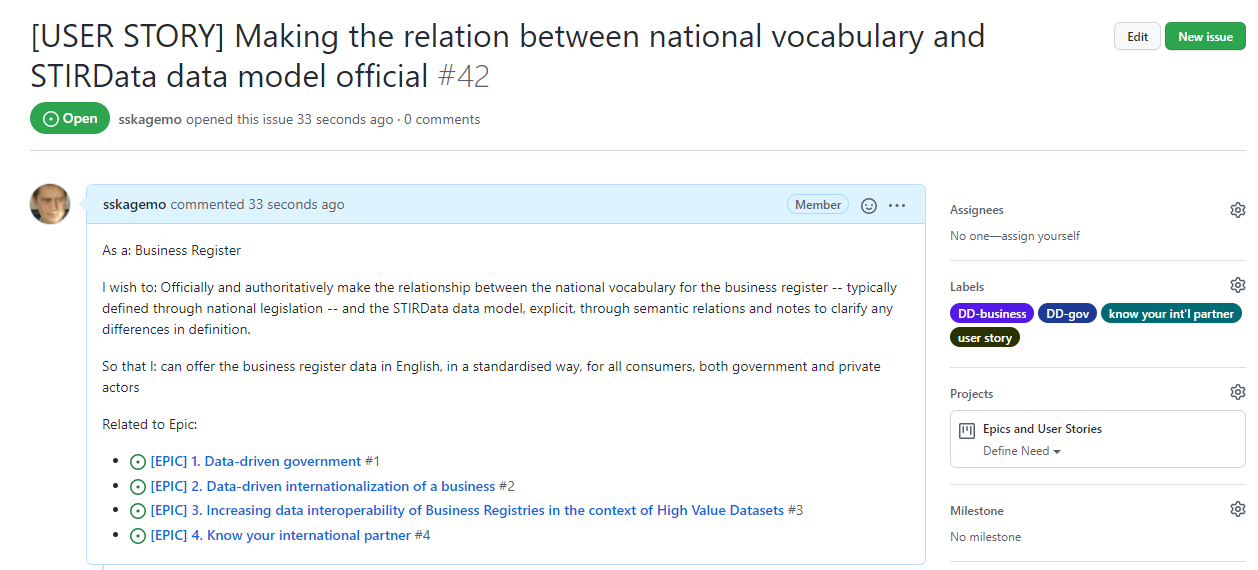
Another group of User Stories is more about giving information about the data, for instance the up-to-dateness (#29) and give an overview the sources (#34), and being able to relate the data the national vocabulary for business register information (#42).
A third group of the User Stories is to allow the consumer to go beyond the capabilities of the platform, and continue analysis or for other purposes store data locally (#33), using their favourite tool for further work (#37), and combining the data with other sources that might be available only for the consumer of the data (#14).
A last group is more about personalising the user experience, such as customising the dashboard (#24), and receiving updates (#25).
Scenario 2: “Data-driven internationalization of a business” (DD-business)
Below is a snapshot of the Epic from https://github.com/STIRData/user-stories/issues/2
As a: Private Company
I wish to: develop my activities into new European countries and wishes to retrieve a geographic distribution of companies providing similar services and retrieve more available information about certain companies it is interested in (e.g. about their representatives, financial statements, etc) .
So that I: interested in learning where competitors, and potential partners, are located, assess their market share, feed the retrieved information into my business analytics algorithms for more in-depth analysis
Comment:
There is also a possibility for companies to specialise in analysing the information and provide insight as a service to other companies, but these companies will of course also benefit from easier access to more data.
For this Scenario, as of March 2022, a total of 8 User Stories have been identified. As mentioned above, as the scenario is similar to Scenario 1 in many ways, except for the role (a company vs a government), there are currently none of the User Stories identified for this scenario that is not also related to Scenario 1. See the scenario 2 on Github for the full list of related User Stories.
Scenario 3: “Increasing data interoperability of Business Registries in the context of High Value Datasets”
This scenario is not yet detailed. We believe the intention of the scenario as it was described in the application is supported through realisation of the other four scenarios.
Scenario 4: “Know your international partner”
Below is a snapshot of the Epic and the attached user stories as of March 2022, from https://github.com/STIRData/user-stories/issues/4
As a: business
I wish to: Get access to information about a potential international partner to determine if this is a serious actor, financial stable, with good governance
So that I: Can reduce the risk before choosing to doing business with a certain partner
Comment: More cross-border trade requires easy access to information about companies cross-border. A very common use case is to verify that a vendor is registered for VAT. The relevant information can also be referred to as "seriousness-information" and has a large potential for improving the market, for instance:
- making it easier for businesses (and their customers) to buy goods and services from actors that are running their business in a serious way (no tax fraud, solid financial situation, respecting workers rights etc)
- reducing the access to the market for non-serious and criminal actors
- levels the playing field for serious actors (does not have to compete with criminals/others that pay too low wages, avoid taxes etc)
- makes it easier for a business to communicate in a trustworthy manner that they run their business in a serious way
For this scenario, as of March 2022, a total of six User Stories have been identified.
Four of these User Stories are related to getting information about a potential trade partner, in order to reduce the risk before starting the trade. This includes basic information about the company (#30), relationship between different companies (parent, subordinate) (#22), and being able to assess the likelihood that a formally correctly registered company is a lawful and serious company (#31). The last one also exists with the roles turned around, as a company that takes compliance seriously and strives to be a serious player, it is important that this can be easily validated by their existing and potential trade partners (#32).
The need for making it easy to assess a potential business partner is identified as a very important element in having a well-functioning market nationally. For instance, in Norway, there is a national program working on establishing services to support this. If such information is easy to access, it also makes it harder for fraudulent companies, and reduces their opportunities to win in un-fair competitions. But the need is even more important for cross-border trade in the Union, as the increase in distance between two potential partners traditionally increases the need for risk-reducing measures.
A general comment is that in this area, we see a trend towards companies using specialised systems for their day to day operations, and the lookup and confirmation of information in Business Registers will often not be done manually, but through a system, and maybe also as part of automatic processes, or self-serve processes. For instance, when ordering in a web shop, the buyer can add only the company identifier, and the webshop will look up more details about the buyer from the relevant Business Register. In such cases there must exists some means to support systems in automatically locating the relevant Business Register and their endpoint to get up-to-date information (#39).
Finally there is a User Story related to the language challenge. In order to easier understand the meaning of the data, it would be beneficial to know how the data (in the English terminology) is related to the national terminology for business register data (#42).
Design for Change: Evolvability
Below is a snapshot of the Epic and the attached user stories as of March 2022, from https://github.com/STIRData/user-stories/issues/5
As a: Data Consumer (Public Administration, Private Company)
I wish: To be able to benefit of added data and functionality when it is provided by different Business Registers around Europe, with as little effort as possible in terms of technical integration/development or costly upgrades of my systems
So that I: Can get immediate value of the data and functionality, from the sources where it is available
For this scenario, as of March 2022, a total of six User Stories have been identified.
The transition to the end-state is an important use-case itself; how do we enable both providers and consumers to adopt the new architecture in steps, and at their own pace?
Therefore there is a need for an architecture that opens up for different models for enabling interoperability, both by having a broad set of options for the registries with the least technical capabilities to make data available, and at the same time allowing other registries to move ahead.
The choice of Linked Data is in itself a way of ensuring evolvability in terms of extending the information model, without breaking existing implementations. A consuming service can perfectly well ignore additional information elements in the payload it receives from an endpoint, as long as the original information elements are recognisable. This limits for instance the need for specific accept-headers with version information, as long as we don’t introduce breaking changes in the vocabularies. Also, by using the European Data Portal as a lookup service to get up to date addresses of which endpoints exist, and what possible future versions they support, new or improved sources can be added and the consuming services can start benefiting from them as soon as they are discovered.
There are four User Stories related to be able to find the endpoint that offers the most up-to-date service, for instance the latest STIRData specification (#38, #12, #13, #39)
Another User Story is related to the need of keeping a an overview of what the status of availability of data in the different countries, which is something that might also function as a push for the Business Registers to implement the latest versions of STIRData, and make more data available (#34).
The last User Story is related to the need for having flexibility in the implementation, while still being compliant with the STIRData specifications (#40).
An open question is whether there will be a need for the architecture to support ways of conveying information about other http operations than GET, and the relevant parameters. This might be the case for instance if there is a need for authentication and authorisation in the future. For this purpose, there are several alternatives, such as HAL (not linked data) or HYDRA (Linked Data). So far we have not identified specific needs for this.
This development is supported by increasing requirements for companies to document their environmental, social and governance (ESG) situation, which will typically also include requiring more information from their subcontractors.
Some selected themes
Columns or rows? For humans or machines?
Analysing a large dataset, or checking facts about a single company? A manual process, or a system automatically verifying information to support another process?
An example of a service and an architecture that is explicitly intended for manually accessing up to date facts about one company, is the Business Register Interconnection System (BRIS). As a person, you can prove you are a human through a captcha-control, and perform searches for information about companies. The search result gives the user the possibility to order PDFs with details about the companies. Machine APIs are on purpose not offered.
Whether you are interested in the columns will typically be a question of whether you are analysing and looking for patterns, insights into a population of businesses or visualising data. In such cases the insights might be valid even if the data is not directly from the source, but a day, week or even a month old.
This is in contrast to when you want specific information about one company, maybe to make a decision on whether you will trust them and send them what they ordered, and invoice them. Knowing that they actually exist, or that they are not in some form of process of dissolution is time-critical.
Also, there might be different requirements on an architecture that should support human lookup, browsing and searching, and an architecture where there are machine-to-machine interaction. In the example above, the company might not do a manual lookup in a search platform to find information about the potential customer, but will use a system that automatically assesses whether the goods should be sent or not, based on access to data. In general, the machine-to-machine interaction requires more precision and higher data quality, whereas a human might be able to interpret descriptions in text correctly.
Often, architectures are related to either-or of these high level use cases. In STIRData we have use cases that cover all variations.

Supporting machine-to-machine interaction, also mean we have to take the developer into account. Typically there exists a system, and a set of developers are employed to maintain and develop it, and the need for integration with STIRData arises. In such cases, it is important that we ensure that it is easy for the developers to do the integration. There are great advantages in using Linked Data as a technology in STIRData, but this should not become an obstacle for developers that need to integrate, and does not have any prior knowledge about Linked Data.
National Business Registers holds data representing national terminology
A main challenge when the aim is to offer data from national registries in a standardised way, with an English vocabulary[2], is to make sure the data matches the vocabulary. Principally, the national concepts are individual concepts, based on national regulation – and therefore they can not have the exact same definition – as that would imply that they actually were the same concepts.
Therefore, we can for instance not relate the national vocabularies to the concept in the STIRData-model as “preferred term”, as this would indicate that the national term referred to the STIRData concept and its definition. Although several concepts can share the same term, and still be different concepts, it increases the risk of creating misunderstandings.
One example that illustrates this is the concept for a company chosen by STIRData. It uses the concept RegisteredOrganization from the Registered Organization Vocabulary:
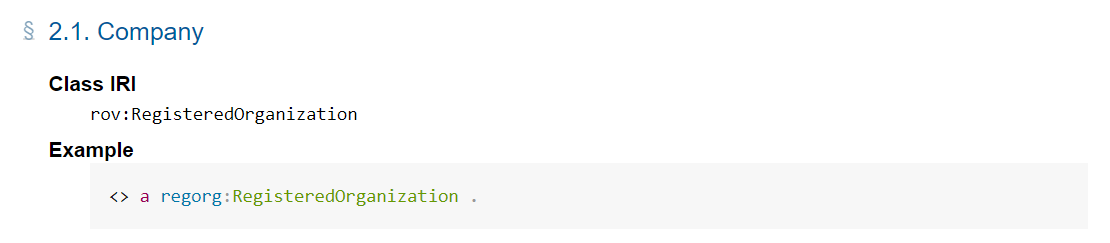
This is a concept that in many ways reflects the subject of interest in a good way; we are interested in companies registered in Business Registries.
At the same time, the definition excludes sole traders:
“The Registered Organization class is central to the vocabulary. It represents an organization that gains legal entity status by the act of registration cf. org:FormalOrganization that applies to any legal entity, including those created by other legal means. In many countries there is a single registry although in others, such as Spain and Germany, multiple registries exist.
Registered organizations are distinct from the broader concept of organizations, groups or, in some jurisdictions, sole traders. Many organizations exist that are not legal entities yet to the outside world they have staff, hierarchies, locations etc. Other organizations exist that are an umbrella for several legal entities (universities are often good examples of this).”
In Norway, The Norwegian Business Register includes sole traders, and they are given an organisation id. In other words, there is a conflict between the definitions of the Norwegian concept and the chosen concept.
A work-around could be to just exclude all the sole traders from the Norwegian data that are exposed in accordance with the STIRData-datamodel. This would solve the semantic conflict. But at the same time, when we look at use cases, we see that for many use cases it is relevant to get information about sole traders, when that information is available. For instance, when receiving an invoice sent by a sole trader, the receiver might want to verify the existence, and other information such as whether the trader is registered for VAT. Also, for data driven government, knowing about the totality of companies that operate is an advantage.
Another way to solve the problem could be by creating a new concept with a new definition to solve this. But then we introduce a new concept when we already have a candidate from an existing, quite well known vocabulary. That would mean we would loose the immediate recognition of the “Registered Organization”-concept.
Choosing a higher level concept, such as org:FormalOrganization, or Agent is another alternative. On one hand this will allow for all differences in national vocabularies. On the other hand, we loose the value of a more specific, immediately recognised concept.
This is one example, but as stated earlier, all national concepts are by their nature different from the concepts in a new, international vocabulary. Therefore we need a method that takes this into account.
The proposed solution to this is to accept the differences, and try to find concepts that have some benefits, such as being well known, well defined, part of existing vocabularies, available as Linked Data etc, and state explicitly that they are not the same as the national concepts, but close to. This can be achieved e.g., using the skos:closeMatch-relation.
That way, a business registry can say officially that there is a relation between the national business register concepts and the STIRData concepts, and in a way that is machine readable.
It could be noted that in practice, data from business registers will often be used with English terms, but the choice of terms are then often taken by others than those who have responsibility for the register. It can typically be made by developers setting up an exchange or external actors, such as commercial information providers.
Nordic Business Terminology
In parallel with the STIRData-project, BRREG is also participating in a Nordic collaboration project, Nordic Smart Government and Business (NSG&B), where there is a need for making business register information from the different Nordic countries available in a standardised manner, so that it is easy to consume cross-border.
Contrary to the STIRData-project, analysis of large amounts of data is not within the scope of the NSG&B-project. It mainly focuses on the use cases similar to the “Know your international partner”-scenario. There are also some differences in what data is (likely to be) available for those use cases, and therefore there might be a different priority of information elements in the NSG&B-work.
Still, the STIRData data model has been an important input to the work. As a first step the NSG&B-project is working on establishing a concept model independent of the concrete data model for information exchange. This concept model will be mapped to the different national concepts using skos:closeMatch (and potentially skos:exactMatch).
The following illustration shows how Norwegian concepts in the Norwegian national concept catalogue can be mapped to the elements in the Nordic Business Terminology (WORK IN PROGRESS)
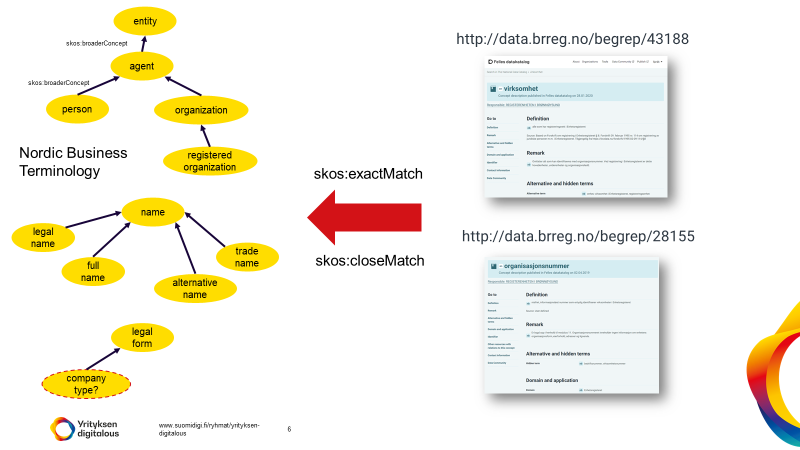
Next step is to establish a reference data model which will be related to relevant international vocabularies to state explicitly how the elements are related, before agreeing on a concrete data model to be implemented in the cross-border services.
The illustration below shows the relation between the concept model (Nordic Business Terminology) and the Reference Data model and the actual data model to be implemented. (WORK IN PROGRESS)
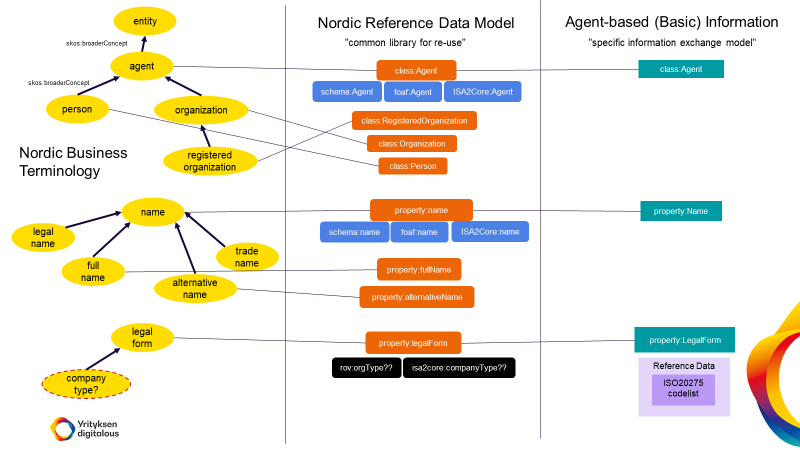
Issue 42 on GitHub represents the use case from the business register perspective; how can a national business registry make the relation between its national concepts, typically regulated in national law, in national languages, and the concepts in the STIRData datamodel?
Beyond Open Data
A development we already see, for instance in Norway and Estonia, are services for sharing government-held data that can not be shared openly, due to confidentiality. These services let the businesses be in control of the sharing themselves, based on consent, in situations where they have the need for it. An example is a company bidding for a tender, and the tendering company has set a requirement that all bidders must show their tax records, to prove they have no tax debts.
Today, this is a manual process, where the bidding company must ask the national Tax Authority for a confirmation letter, and add it as part of the tender. In Norway, a service called “eBevis” lets the bidding company consent in the tendering company accessing these data directly from the Tax Authority, reducing the manual work, as well as the risk of out-dated or falsified confirmation letters. Currently the service can only be used in public procurement (G2B), but also in B2B-procurement there is a need for the exact same information.
Although the STIRData platform currently only supports Open Data, having a roadmap to add support for non-open data through mechanisms for authentication, authorisation and consent based sharing of data, is likely to be important in order to make sure the STIRData platform stays relevant in the future. This is also in accordance with the new initiatives in the EU, such as the Data Governance Act, that proposes mechanisms to ensure that also non-open governmental data can be shared, for instance through consent. See for instance article 5, point 6:
Where the re-use of data cannot be granted in accordance with the obligations laid down in paragraphs 3 to 5 and there is no other legal basis for transmitting the data under Regulation (EU) 2016/679, the public sector body shall support re-users in seeking consent of the data subjects and/or permission from the legal entities whose rights and interests may be affected by such re-use, where it is feasible without disproportionate cost for the public sector. In that task they may be assisted by the competent bodies referred to in Article 7 (1).
There are User Stories related to this subject in Scenario 4 - Know Your International Partner.
Datasets
This section describes the datasets that were considered for inclusion in the STIRData platform and could be used for implementing parts of the above described use cases. The considered datasets are business registry datasets from several European countries that are made available from the respective registries as open data. It should be noted that many European country registers do not provide free access to their full set of data, so the list in this section is limited to the countries that do provide such access.
The datasets described below were used as the input to transformation pipelines converting the data to RDF representations according to the STIRData model. Several registers provide search-based access to their data, i.e. one can retrieve company details by providing a name or identifier. This type of access is not sufficient for STIRData; since datasets are to be transformed in an RDF representation, it is needed that the entire register dataset can be downloaded, so that the necessary transformations can be applied in bulk.
In the following, for each dataset, we provide information about the registry providing the data, the links from which the data can be downloaded, the licensing, the update frequency and the format and size of the data. We also include a short description of the fields included in each dataset so as to show what kind of information each registry provides. Links to auxiliary information that facilitate the interpretation of the data are also provided when available (e.g. documents explaining the data fields, documents with closed list values, etc.)
Finally, based on the description and the analysis of the data fields, for each registry data we provide its characterization along a set of dimensions that are of particular relevance to STIRData, namely
- Entity types: Types of entities that are included in the dataset, e.g. main legal entities, establishments, branches, etc.
- Legal/Natural persons: All datasets include registered legal persons, but some include data also about natural persons (sole traders).
- Names: Types of available names for legal entities. Apart from the legal name some registers provide trading names, or abbreviated names.
- Identifiers: Types of available identifiers. Usually the registry identifier is provided, but some datasets also provide tax and other identifiers.
- Registration date: It indicates whether a registration date is provided.
- Dissolution date: It indicates whether a dissolution date is provided. Most registries provide information only about currently registered entries. Dissolved and deregistered companies are in most cases not included in the data. The presence of a dissolution date indicates that the dataset contain also historic data, i.e. data about dissolved companies.
- Business activities: It indicates whether business activity codes are available. The business activity codes should be NACE or national NACE extension codes. The number of provided business activity codes are provided as well as their characterization, if any (main, secondary, auxiliary).
- Address: It indicates what types of addresses are available (e.g. business, postal address).
- Legal form: It indicates whether the legal form of each legal entity is provided. The possible legal forms for each country are usually a closed list of values.
- Legal status: It indicates whether information about the current status of the company is provided (e.g. active, in liquidation, etc.)
- Foreign entities: It indicates whether the dataset includes entities whose base registration is in a foreign country.
Belgium
The dataset is made available by the Crossroads Bank for Enterprises (CBE, BCE).
It may be accessed through the CBE open data page (https://economie.fgov.be/en/themes/enterprises/crossroads-bank-enterprises/services-everyone/cbe-open-data). To get access to the public data a free registration is required.
It is provided with the Licence OPEN DATA license and it is updated monthly.
The dataset comes in the form of a set of CSV files, which includes only currently registered entities. Files with the monthly changes (additions, removals) are provided, however without including the exact date information of the change. The registered entities are divided into enterprises, establishments and branches. Separate files with basic registration information for each entity type is provided. Address, contact, activity and denomination information are also provided in separate files. The files follow a relational database structure.
As of 04/03/2022, the files contained 1,854,128 enterprises, 1,589,833 establishments and 7,443 branches.
The several fields contained in the dataset files are summarized in the following table.
|
Field name |
Description |
|
EnterpriseNumber |
Enterprise number |
|
EstablishmentNumber |
Establishment number |
|
Id |
Branch number |
|
Status |
Entity status (active) |
|
JuridicalSituation |
Legal status |
|
TypeOfEnterprise |
Type of enterprise (legal or natural person) |
|
JuridicalForm |
Legal form |
|
StartDate |
Registration date |
|
Denomination |
Denomination |
|
TypeOfDenomination |
Type of denomination (e.g. name, abbreviation) |
|
Language |
Denomination language |
|
ActivityGroup |
Business activity group |
|
NaceVersion |
Business activity NACE version |
|
NaceCode |
Business activity NACE code |
|
Classification |
Business activity classification (main, secondary etc.) |
|
TypeOfAddress |
Address type |
|
CountryNL, CountryFR |
Address country |
|
Zipcode |
Address postcode |
|
MunicipalityNL, MunicipalityFR |
Address municipality |
|
StreetNL, StreetFR |
Address street |
|
HouseNumber |
Address house number |
|
Box |
Address postbox |
|
ExtraAddressInfo |
Extra address info |
|
DateStrikingOff |
Striking off date |
|
ContactType |
Contact type (e.g. telephone, web, email) |
|
Value |
Actual contact value |
A file with the allowed values for the fields that are closed list value fields (e.g. Classification,ContactType, etc) are also provided. The same file includes also the business activity, legal form and legal status codes. The business activity codes are provided in CSV format by STATBEL as the NACE-BEL2008 Classification, The legal form and legal status codes are provided also in XLSX format by FPS economie (link).
The analysis of the provided data along the dimensions of interest is summarised in the following table.
|
Dimension |
Values |
|
Entity types |
Enterprises, establishments, branches |
|
Legal/Natural persons |
Legal persons and natural persons |
|
Names |
Legal name, trading name, abbreviation |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
YES |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
Czechia
The Czech business registry dataset is in fact split into multiple datasets by year, region and legal entity type. The individual datasets are made available at the portal of the Ministry of Justice of the Czech Republic (https://dataor.justice.cz/). The datasets were also available via the Czech National Open Data Portal and the Official portal for European data, but that is currently not the case, and the Ministry of Justice is working on registering their open data catalogue with the national one at the moment. The datasets are distributed as XML and CSV files under an open data license (https://dataor.justice.cz/files/ISVR_OpenData_Podminky_uziti.pdf - in Czech).
As part of the STIRData project, a semantically lifting pipeline was implemented, transforming the original XML version of the files into a proper RDF version according to a Czech Semantic Government Vocabulary - an OWL ontology based on the Unified Foundational Ontology (UFO) and the Czech legislation. This transformed version is then the source for the conversion to a STIRData specification compliant version.
Therefore, we identify the relevant fields using their Czech Semantic Government Vocabulary IRIs.
Used prefixes:
@prefix vr: <https://slovník.gov.cz/legislativní/sbírka/304/2013/pojem/> .
@prefix ok: <https://slovník.gov.cz/legislativní/sbírka/90/2012/pojem/> .
@prefix oz: <https://slovník.gov.cz/legislativní/sbírka/89/2012/pojem/> .
@prefix zr: <https://slovník.gov.cz/legislativní/sbírka/111/2009/pojem/> .
@prefix or: <https://slovník.gov.cz/datový/obchodní-rejstřík/pojem/> .
@prefix schema-s: <https://schema.org/> .
|
Predicate IRI |
Description |
|
Legal entity name |
|
|
Legal entity code |
|
|
Legal form |
|
|
Registered address (?address) |
|
|
Registration date |
|
|
Dissolution date |
|
|
?address/zr:má-název-části-obce |
Registered address - Name of part of municipality |
|
?address/zr:má-název-ulice |
Registered address - Street name |
|
?address/or:má-poštovní-směrovací-číslo |
Registered address - Post code |
|
?address/zr:číslo-popisné |
Registered address - House number (description) |
|
?address/zr:číslo-orientační |
Registered address - House number (orientation) |
|
Registered address - Municipality / military district name |
|
|
?address/or:má-název-státu |
Registered address - Country name |
|
?address/zr:má-název-okresu |
Registered address - District name |
The analysis of the provided data along the dimensions of interest is summarised in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons and natural persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
YES |
|
Business activities |
NO |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
NO |
|
Foreign entities |
YES |
There is also a second dataset, Registry of economic subjects published by the Czech Statistical Office, which contains mapping of the Czech legal entities to NACE codes. It is available in the Czech National Open Data Portal and in the Official portal for European data.
Cyprus
The dataset is made available by the Department of Registrar of Companies and Intellectual Property of CyprusMinistry of Energy, Commerce and Industry.
It may be accessed through the Cyprus open data page (link) and through the European data portal (https://data.europa.eu/data/datasets/340dbc18-9d24-4156-857a-607617412b83).
It is provided with a CC 4.0 BY license and it is updated monthly.
The dataset comes in the form of three CSV files, once containing company registration info, one containing company addresses, and one containing company officers details. The dataset includes also historic data, i.e. also dissolved entities. As of 25/02/2022, the dataset contained 497,350 entries.
The several fields contained in the dataset files are summarized in the following table.
|
Field name |
Description |
|
ORGANISATION_NAME |
Legal entity name |
|
REGISTRATION_NO |
Legal entity registration number |
|
ORGANISATION_TYPE_CODE |
Legal form (code) |
|
ORGANISATION_TYPE |
Legal form (name) |
|
ORGANISATION_SUB_TYPE |
Legal form subtype |
|
NAME_STATUS_CODE |
Name status (code) |
|
NAME_STATUS |
Name status (name) |
|
REGISTRATION_DATE |
Registration date |
|
ORGANISATION_STATUS |
Legal status |
|
ORGANISATION_STATUS_DATE |
Legal status change date |
|
ADDRESS_SEQ_NO |
Address identifier |
|
STREET |
Address street and number |
|
BUILDING |
Address building |
|
TERRITORY |
Address city and country |
|
PERSON_OR_ORGANISATION_NAME |
Person of organization (official) name |
|
OFFICIAL_POSITION |
Official position |
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
YES |
|
Business activities |
NO |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
Estonia
The dataset is made available by the Estonian Centre of Registers and Information Systems (Registrite ja Infosüsteemide Keskus, RIK).
It may be accessed through the RIK open data page (https://www.rik.ee/en/open-data) as the information system called Commercial Register.
It is provided with a CC 3.0 BY-SA license and it is updated daily.
The dataset comes in the form of a single CSV or XML file (CSV link 1, XML link), which includes only currently registered entities. As of 11/03/2022, it contained 336,022 entries.
The several fields contained in the dataset files are summarized in the following table.
|
Field name |
Description |
|
nimi |
Legal entity name |
|
ariregistri_kood |
Legal entity code |
|
ettevotja_oiguslik_vorm |
Legal form |
|
ettevotja_oigusliku_vormi_alaliik |
Legal form subtype |
|
kmkr_nr |
KMKR number (VAT number) |
|
ettevotja_staatus |
Registration status (code) |
|
ettevotja_staatus_tekstina |
Registration status (name) |
|
ettevotja_esmakande_kpv |
Start date |
|
ettevotja_aadress |
empty |
|
asukoht_ettevotja_aadressis |
Address location |
|
asukoha_ehak_kood |
Address latvian administrative unit identifier |
|
asukoha_ehak_tekstina |
Address latvian administrative unit name |
|
indeks_ettevotja_aadressis |
Address postcode |
|
ads_adr_id |
Address identifier |
|
ads_ads_oid |
empty |
|
ads_normaliseeritud_taisaadress |
Full address |
|
teabesysteemi_link |
Information system link |
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier, tax identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
NO |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
NO |
Finland
The dataset is made available by the Finnish National Board of Patents and Registration (PRH).
It may be accessed through the finnish open data portal (https://www.avoindata.fi/data/fi/dataset/yritykset/resource/98db020d-2dea-4fcd-a421-9e2ef0d396ab).
It is provided with a CC BY 4.0 license and it is updated monthly.
The dataset comes in the form of a single CSV file, which includes only current data. As of 13/02/2022, the dataset (link) contained 329,238 entries.
The several fields contained in the dataset files are summarized in the following table (their explanation in latvian is provided here).
|
Field name |
Description |
|
company_name |
Legal entity name |
|
business_id |
Legal entity number |
|
company_form |
Legal form |
|
business_line_code |
Business activity (code) |
|
business_line_name |
Business activity (name) |
|
registration_date |
Registration date |
|
postal_address |
Postal address street and number |
|
postal_post_code |
Postal address postcode |
|
postal_city |
Postal address city |
|
street_address |
Street address street and number |
|
street_post_code |
Street address postcode |
|
street_city |
Street address city |
|
liquidation |
Liquidation state |
|
registered office |
Registered office |
The business activity codes are provided in CSV format by Statistics Finland as the Standard Industrial Classification TOL 2008.
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
1 |
|
Addresses |
Postal address, street address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
France
The dataset is made available by the French National Institute of Statistics and Economic Studie (INSEE) as the Sirene database.
It may be accessed through the French open data page (https://www.data.gouv.fr/en/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/) and the European data portal (https://data.europa.eu/data/datasets/5b7ffc618b4c4169d30727e0).
It is provided with a Licence Ouverte / Open Licence version 2.0 license and it is updated monthly.
The dataset includes information about legal entities and establishments and comes in the form of five CSV files, including detailed historical data (changes). Extensive documentation on the contents of each file is also included in the dataset. As of 1/03/2022, it contained 22,962,279 legal entities and 32,493,014 establishments..
The files contain several describing several aspects of a legal entity or establishment. The main fields of interest are summarized in the following table.
|
Field name |
Description |
|
siren |
Siren number |
|
unitePurgeeUniteLegale |
Legal entity dissolution date |
|
dateCreationUniteLegale |
Legal entity creation date |
|
sigleUniteLegale |
Legal name abbreviated name |
|
sexeUniteLegale |
Natural person sex |
|
prenom1UniteLegale … prenom4UniteLegale |
Natural person surnames |
|
prenomUsuelUniteLegale |
Natural person trading surname |
|
pseudonymeUniteLegale |
Natural person pseudonym |
|
identifiantAssociationUniteLegale |
Number in Répertoire National des Associations (RNA) |
|
dateDebut |
Start date |
|
nomUniteLegale |
Natural person name |
|
nomUsageUniteLegale |
Natural person trading name |
|
denominationUniteLegale |
Legal person name |
|
denominationUsuelle1UniteLegale… denominationUsuelle4UniteLegale |
Legal person trading names |
|
categorieJuridiqueUniteLegale |
Legal form |
|
activitePrincipaleUniteLegale |
Primary business activity (code) |
|
nomenclatureActivitePrincipaleUniteLegale |
Primary business activity (name) |
|
siret |
Establishment number |
|
dateCreationEtablissement |
Establishment creation date |
|
etablissementSiege |
Establishment main address or not |
|
complementAdresseEtablissement, complementAdresse2Etablissement |
Establishment address complement |
|
numeroVoieEtablissement, numeroVoie2Etablissement |
Establishment address number |
|
indiceRepetitionEtablissement, indiceRepetition2Etablissement |
Establishment address repetition index |
|
typeVoieEtablissement, typeVoie2Etablissement |
Establishment address street type (code) |
|
libelleVoieEtablissement, libelleVoie2Etablissement |
Establishment address street type (name) |
|
codePostalEtablissement, codePostal2Etablissement |
Establishment address postcode |
|
libelleCommuneEtablissement, libelleCommune2Etablissement |
Establishment address city |
|
libelleCommuneEtrangerEtablissement, libelleCommuneEtranger2Etablissement |
Establishment foreign address city |
|
codeCommuneEtablissement, codeCommune2Etablissement |
Establishment address region code |
|
codePaysEtrangerEtablissement, codePaysEtranger2Etablissement |
Establishment address foreign country (code) |
|
libellePaysEtrangerEtablissement, libellePaysEtranger2Etablissement |
Establishment address foreign country (name) |
|
libellePaysEtrangerEtablissement… enseigne3Etablissement |
Establishment sign |
|
denominationUsuelleEtablissement |
Establishment trading name |
|
activitePrincipaleEtablissement |
Establishment principal business activity (code) |
|
nomenclatureActivitePrincipaleEtablissement |
Establishment principal business activity (name) |
The business activity and organisation form codes are provided in XLSX format by INSEE as the Nomenclature d’activités française – NAF rév. 2 and Catégories juridiques.
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Enterprises, establishments |
|
Legal/Natural persons |
Legal persons and natural persons |
|
Names |
Legal name, trading name, abbreviated name, natural person names |
|
Identifiers |
Register identifier, RNA identifier |
|
Registration date |
YES |
|
Dissolution date |
YES |
|
Business activities |
1 primary, 1 secondary |
|
Addresses |
Primary and secondary address (at the establishment level) |
|
Legal form |
YES |
|
Legal status |
NO |
|
Foreign entities |
YES |
Greece
Greek business data are provided by the General Commercial Registry of Greece. The registry does not provide its data for bulk download, but provides a search page.
In the content of STIRData project, a subset of the above data, referring to the Athens area, were provided by one of the project partners, namely the Athens Chamber of Commerce and Industry.
The business activity codes are provided in XLSX format by the Greek Independent Authority for Public Revenue (link).
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier, chamber identifier, tax identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
main, secondary, auxiliary |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
Latvia
The dataset is made available by the Register Enterprise of the Republic of Latvia (Latvijas Republikas Uzņēmumu reģistrs).
It may be accessed through the Latvian data portal (https://data.gov.lv/dati/lv/dataset/uz) and the European data portal (https://data.europa.eu/data/datasets/4de9697f-850b-45ec-8bba-61fa09ce932f).
It is provided with a CC0 1.0 license and it is updated daily.
The dataset comes in the form of a single CSV file (link 1, link 2), which also includes historic data, i.e. also dissolved entities. As of 10/03/2022, it contained 439,568 entries.
The several fields contained in the dataset files are summarized in the following table (their explanation in latvian is provided here).
|
Field name |
Description |
|
regcode |
Legal entity registration number |
|
sepa |
SEPA identifier |
|
name |
Full name of the legal entity |
|
name_before_quotes |
Name before the quotes |
|
name_in_quotes |
Name in quotes |
|
name_after_quotes |
Name after the quotes |
|
without_quotes |
Indicates where there are no quotes in the full name |
|
regtype |
Registration type (code) |
|
regtype_text |
Registration type (name) |
|
type |
Type of legal entity (code) |
|
type_text |
Type of legal entity (name) |
|
registered |
Registration date |
|
terminated |
Termination date (or date of reorganization) |
|
closed |
Reason for exclusion (liquidation, reorganization) |
|
address |
Full address |
|
index |
Postcode |
|
addressid |
Address code in the state address register |
|
region |
Address county |
|
city |
Address city |
|
atvk |
Legal address latvian administrative unit identifier |
|
reregistration_term |
Deadline for registration of religious organizations that carry out re-registration |
The values of closed list values fields (e.g. regtype, type) are provided in this link.
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
YES |
|
Business activities |
NO |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
NO |
|
Foreign entities |
NO |
Norway
The dataset is made available by the The Brønnøysund Register Centre (BRREG).
It may be accessed through the BREGG open data page (https://data.brreg.no/enhetsregisteret/oppslag/enheter). It is available for bulk download but an API is also provided.
It is provided with a Norwegian License for Public Data (NLOD) and it is updated daily.
The bulk download dataset comes in the form of two JSON or XLSX files, one including main units (JSON link, XLSX link), and a second one including subunits (JSON link, XLSX link). The files include only currently registered entities. Register changes and updates can be obtained through the API. As of 10/03/2022, the data contained 1,071,514 main units and 749,946 subunits.
The several fields contained in the dataset files are summarized in the following table
|
Field name |
Description |
|
Organisasjonsnummer |
Legal entity number |
|
Navn |
Legal entity name |
|
Organisasjonsform.kode |
Legal entity form (code) |
|
Organisasjonsform.beskrivelse |
Legal entity form (name) |
|
Næringskode 1 … Næringskode 3 |
Business activities (codes) |
|
Næringskode 1.beskrivelse … Næringskode 3.beskrivelse |
Business activities (names) |
|
Hjelpeenhetskode |
Auxiliary activity (code) |
|
Hjelpeenhetskode.beskrivelse |
Auxiliary activity (name) |
|
Antall ansatte |
Number of employees |
|
Hjemmeside |
Company URL |
|
Postadresse.adresse |
Postal address street and number |
|
Postadresse.poststed |
Postal address post office |
|
Postadresse.postnummer |
Postal address postcode |
|
Postadresse.kommune |
Postal address municipality (name) |
|
Postadresse.kommunenummer |
Postal address municipality (number) |
|
Postadresse.land |
Postal address country (name) |
|
Postadresse.landkode |
Postal address country (code) |
|
Forretningsadresse.adresse |
Business address street and number |
|
Forretningsadresse.poststed |
Business address post office |
|
Forretningsadresse.postnummer |
Business address postcode |
|
Forretningsadresse.kommune |
Business address municipality (name) |
|
Forretningsadresse.kommunenummer |
Business address municipality (number) |
|
Forretningsadresse.land |
Business address country (name) |
|
Forretningsadresse.landkode |
Business address country (code) |
|
Institusjonell sektorkode |
Industrial sector (code) |
|
Institusjonell sektorkode.beskrivelse |
Industrial sector (name) |
|
Siste innsendte årsregnskap |
Last submitted annual accounts |
|
Registreringsdato i Enhetsregisteret |
Registration date |
|
Stiftelsesdato |
Foundation date |
|
FrivilligRegistrertIMvaregisteret |
Voluntary registered in the food register |
|
Registrert i MVA-registeret |
Registered in the VAT register |
|
Registrert i Frivillighetsregisteret |
Registered in the volunteer register |
|
Registrert i Foretaksregisteret |
Registered in the register of business enterprises |
|
Registrert i Stiftelsesregisteret |
Registered in the foundation register |
|
Konkurs |
Bankrupt |
|
Under avvikling |
In liquidation |
|
Under tvangsavvikling eller tvangsoppløsning |
In forced liquidation or forced dissolution |
|
Overordnet enhet i offentlig sektor |
Superior unit in the public sector |
|
Målform |
Language form |
The business activity, organisation form and industrial sector codes are provided in CSV format by Statistics Norway as the Standard Industrial Classification and Organization Form Classification and Institutional Sector Classification.
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Main units, subunits |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
1 - 3 main activities, 1 auxiliary activity |
|
Addresses |
Postal address, business address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
Romania
The dataset is made available by the National Trade Register Office of the Romanian Ministry of Justice (Oficiul Național al Registrului Comerțului, ONRC).
It may be accessed through the Romanian data portal and the European data portal.
It is provided with the CC 4.0 BY license and it is updated four times a year (February, May, September, December).
The dataset is split in four CSV files, one containing registered entities without business address, one containing deregistered entities without business address, one containing registered entities with business address and one containing deregistered entities with business address. The dataset includes also a CSV file with the legal entity status codes.
The dataset does not have a fixed URI, and each update corresponds to a new dataset. The 9 February 2002 dataset is available in the Romanian data portal (https://data.gov.ro/dataset/firme-inregistrate-la-registrul-comertului-pana-la-data-de-09-februarie-2022) and in the European data portal (https://data.europa.eu/data/datasets/ef5df1b5-9f4a-447f-822b-4b00667a100f)
As of 09/02/2022, the dataset contained 60 registered entries without business address, 61 deregistered entries without business address, 1,740,192 registered entries with business address and 1798841 deregistered entries with business address.
The several fields contained in the dataset files are summarized in the following table
|
Field name |
Description |
|
DENUMIRE |
Legal entity name |
|
CUI |
Unique registration number |
|
COD_INMATRICULARE |
Registration code |
|
EUID |
European unique identifier |
|
STARE_FIRMA |
Legas status code |
|
ADRESA_COMPLETA |
Full address |
|
ADR_TARA |
Address country |
|
ADR_LOCALITATE |
Address municipality |
|
ADR_JUDET |
Address county |
|
ADR_DEN_STRADA |
Address street |
|
ADR_DEN_NR_STRADA |
Address street number |
|
ADR_BLOCADR_SCARA |
Address block number |
|
ADR_ETAJ |
Address follor |
|
ADR_APARTAMENT |
Address apartment |
|
ADR_COD_POSTAL |
Address postcode |
|
ADR_SECTOR |
Address sector |
|
ADR_COMPLETARE |
Address complement |
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier, EUID |
|
Registration date |
NO |
|
Dissolution date |
NO |
|
Business activities |
NO |
|
Addresses |
Registered address |
|
Legal form |
NO |
|
Legal status |
YES |
|
Foreign entities |
NO |
United Kingdom
The dataset is made available by the Companies House.
It may be accessed through the Companies House Free Company Data Product page (http://download.companieshouse.gov.uk/en_output.html).
It is updated monthly.
The dataset comes in the form of a single CSV or a set of smaller CSV files, which includes only currently registered entities. The download link changes each month. As of 01/03/2022, the single CSV file (link) contained 5,039,254 entries.
The several fields contained in the dataset files are summarized in the following table
|
Field name |
Description |
|
CompanyName |
Legal entity name |
|
CompanyNumber |
Legal entity number |
|
RegAddress.CareOf |
Registered address care of |
|
RegAddress.POBox |
Registered address post box |
|
RegAddress.AddressLine1 |
Registered address line 1 |
|
RegAddress.AddressLine2 |
Registered address line 2 |
|
RegAddress.PostTown |
Registered address town |
|
RegAddress.County |
Registered address county |
|
RegAddress.Country |
Registered address country |
|
RegAddress.PostCode |
Registered address postcode |
|
CompanyCategory |
Legal form |
|
CompanyStatus |
Company status (active or not) |
|
CountryOfOrigin |
Country of origin |
|
DissolutionDate |
Dissolution date (empty) |
|
IncorporationDate |
Incorporation date |
|
Accounts.AccountRefDay |
Accounting reference date (day) |
|
Accounts.AccountRefMonth |
Accounting reference date (month) |
|
Accounts.NextDueDate |
Accounts next due date |
|
Accounts.LastMadeUpDate |
Last accounts date |
|
Accounts.AccountCategory |
Accounts category |
|
Returns.NextDueDate |
Annual returns next due date |
|
Returns.LastMadeUpDate |
Annual returns last date |
|
Mortgages.NumMortCharges |
Number of mortgage charges |
|
Mortgages.NumMortOutstanding |
Number of outstanding mortgages |
|
Mortgages.NumMortPartSatisfied |
Number of partially satisfied mortgages |
|
Mortgages.NumMortSatisfied |
Number of satisfied mortgages |
|
SICCode.SicText_1 … SICCode.SicText_4 |
Activity codes and names |
|
LimitedPartnerships.NumGenPartners |
Limited partnerships number of general partners |
|
LimitedPartnerships.NumLimPartners |
Limited partnerships number of limited partners |
|
URI |
Companies house company uri |
|
PreviousName_1.CONDATE … PreviousName_10.CONDATE |
Previous names change date |
|
PreviousName_1.CompanyName .. PreviousName_10.CompanyName |
Previous names |
|
ConfStmtNextDueDate |
Confirmation statement next due date |
|
ConfStmtLastMadeUpDate |
Confirmation statement last date |
A detailed description of the fields and of their values is also provided in this link.
The business activity codes are provided in XLSX format by the Office of National Statistics as the UK SIC 2007 Classification.
The analysis of the provided data along the dimensions of interest is summarized in the following table.
|
Dimension |
Values |
|
Entity types |
Companies |
|
Legal/Natural persons |
Legal persons |
|
Names |
Legal name |
|
Identifiers |
Register identifier |
|
Registration date |
YES |
|
Dissolution date |
NO |
|
Business activities |
1 - 4 |
|
Addresses |
Registered address |
|
Legal form |
YES |
|
Legal status |
YES |
|
Foreign entities |
YES |
Datasets or other sources for enrichment
The business registry datasets described above were used as the source data for obtaining RDF representations of business entities. As discussed above, several datasets include information about the location (address) of each company and its business activities. This information is a potential source of enrichment of the original data by linking business entities to location and business activity information using common vocabularies.
With respect to location information, enrichment can be achieved by mapping addresses to the NUTS and LAU regions provided by Eurostat. The respective data are provided by Eurostat as XLSX files (as of March 2022, the most recent versions are NUTS classification and LAUs). Given that the encoding of address information among the several datasets is not uniform, an appropriate way to perform such linking is by using postcode information. Mappings from postcodes to NUTS and LAU regions are provided by GISCO (link).
With respect to business activities, Eurostat provides the NACE Rev 2 Classification in CSV and XML format. The english version is provided here and here, respectively. Business registries encode business activity information using national extensions of that classifications. The links to each national NACE extension were included, where relevant, in the information about each country dataset in the preceding sections.
Registration of datasets in the European Data Portal
DCAT-AP registration template
An example of a metadata record used to register the Czech business registry dataset compliant with the STIRData specification along with the SPARQL query used to find it in the Official portal for European data can be seen in the STIRData business data model specification.
- This is the record in the University’s local catalog: https://lkod.mff.cuni.cz/zdroj/datové-sady/STIRData/obchodní-rejstřík-stirdata
- This is the harvested record in the Czech National Open Data Catalog (UI): https://data.gov.cz/datová-sada?iri=https%3A%2F%2Fdata.gov.cz%2Fzdroj%2Fdatové-sady%2F00216208%2Fe9a83e226dc746c02dd05aa4688359ad
- This is the harvested record in the Official portal for European data (UI): https://data.europa.eu/data/datasets/https-lkod-mff-cuni-cz-zdroj-datove-sady-stirdata-obchodni-rejstr-i-k-stirdata?locale=en
- This is the harvested record in the Official portal for European data (RDF Turtle): https://data.europa.eu/api/hub/repo/datasets/https-lkod-mff-cuni-cz-zdroj-datove-sady-stirdata-obchodni-rejstr-i-k-stirdata.ttl?useNormalizedId=true&locale=en
[1] STIRData PartD Annex1 Use Cases
[2] Standardising on an English vocabulary is of course not the cause of the problem – it would be the same for any language chosen.