Evaluation
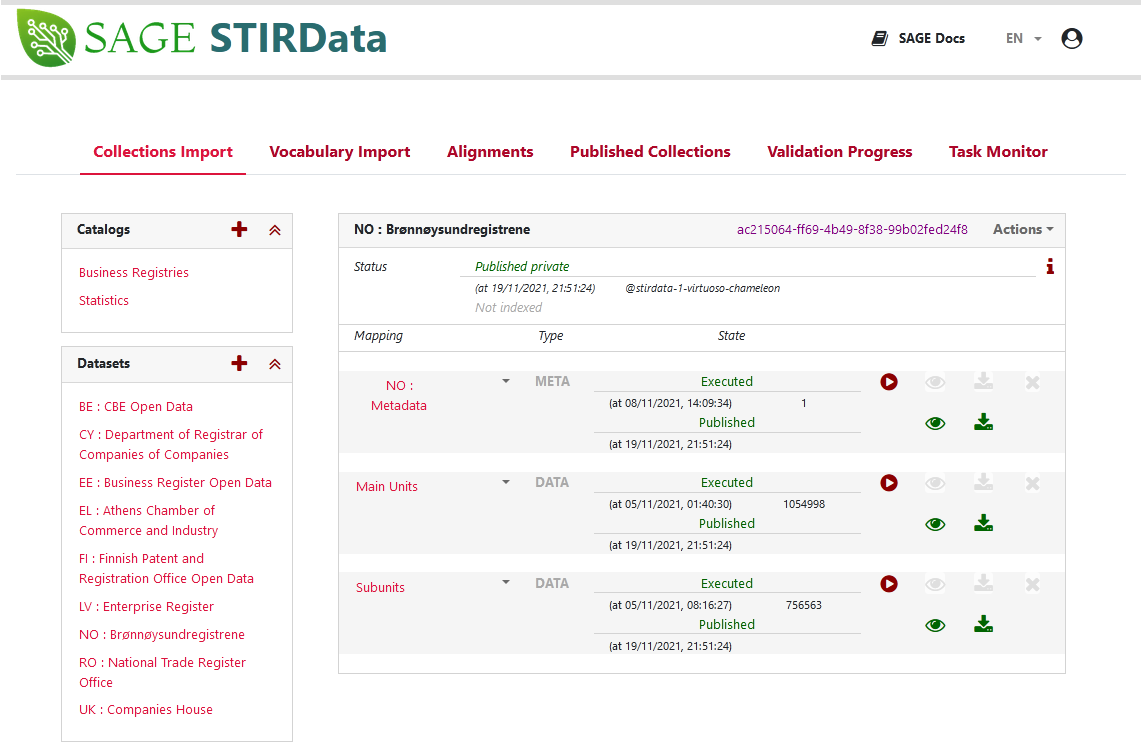
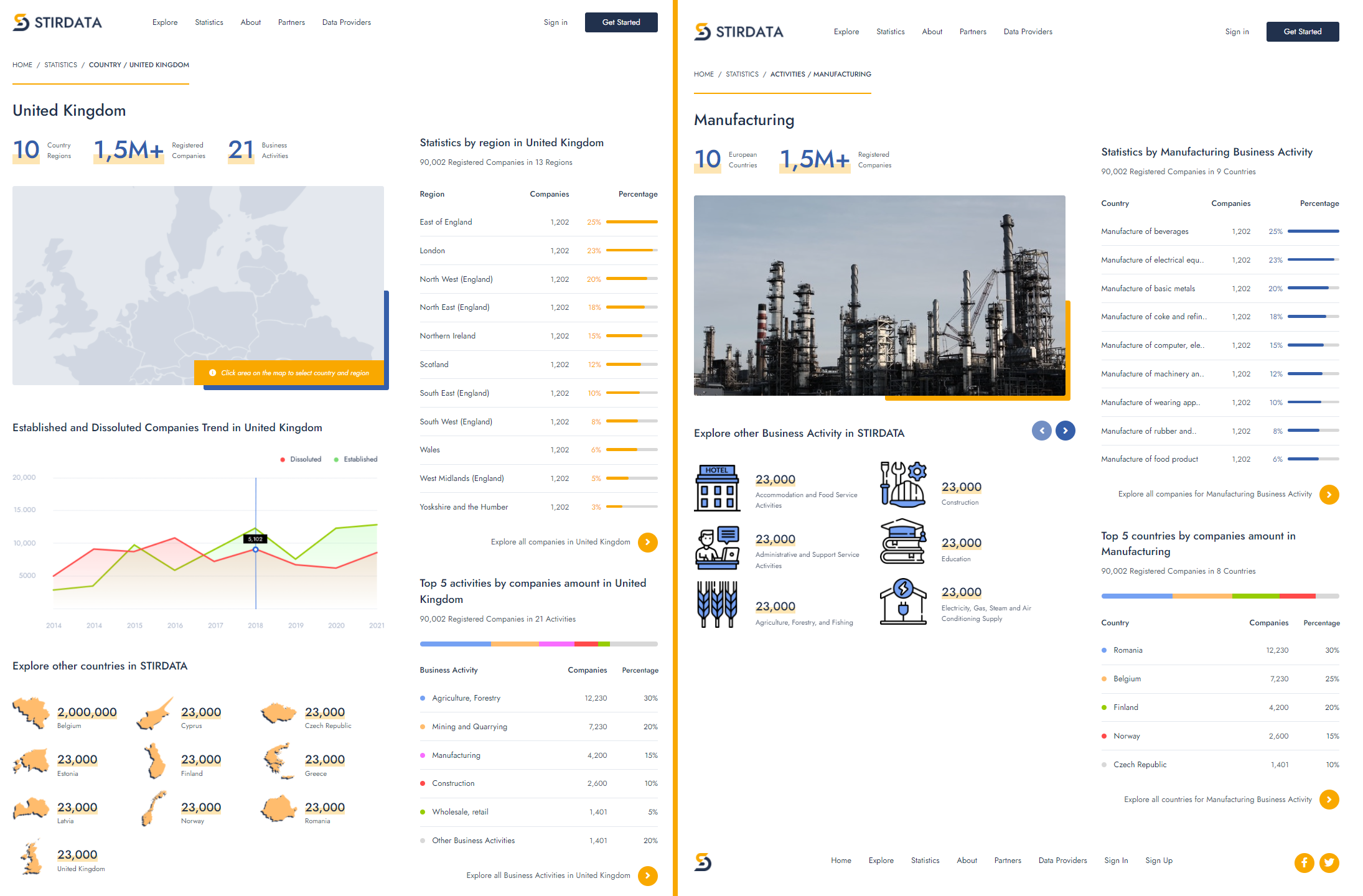
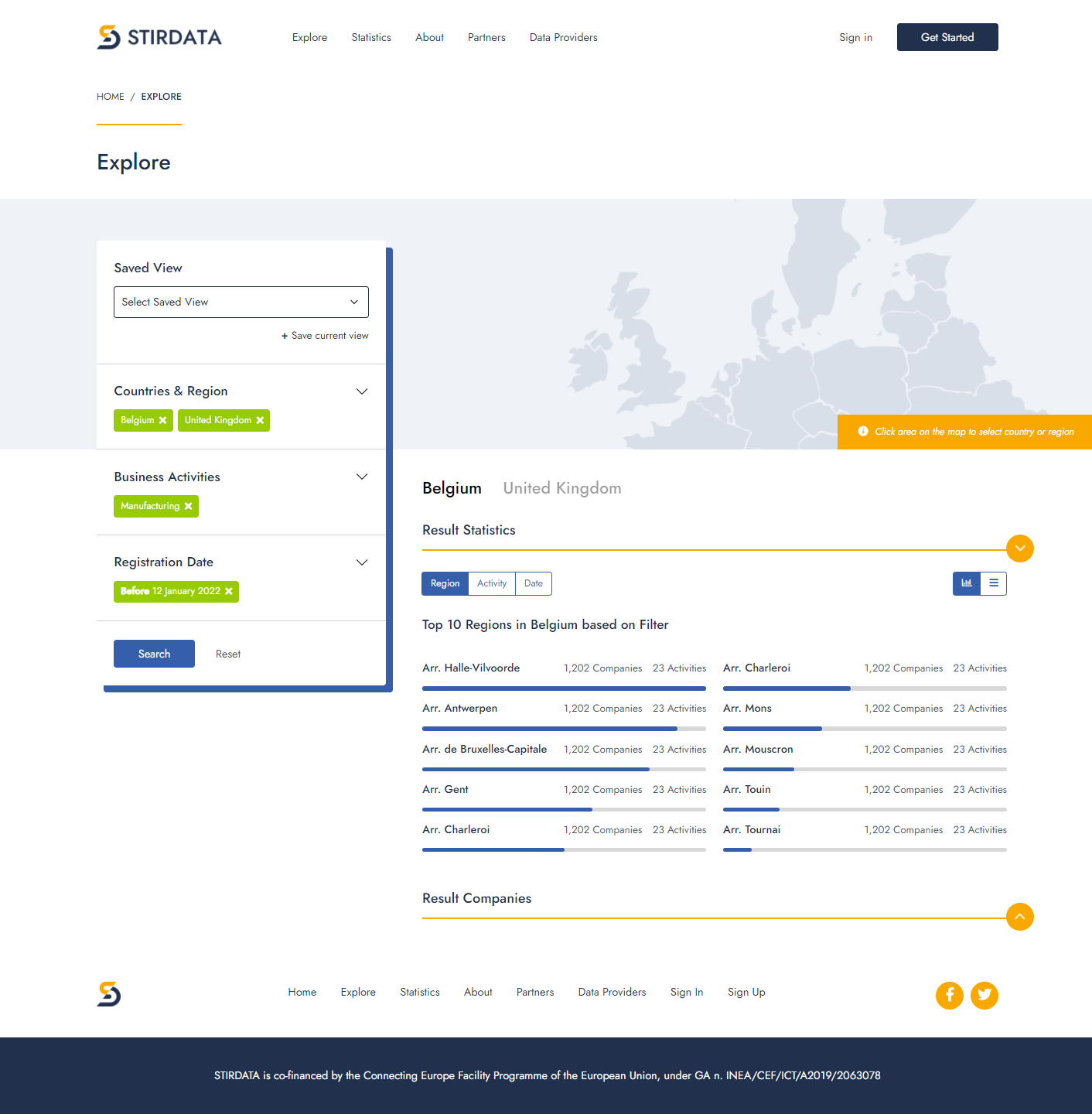
D2RML and the D2RML processor/SAGE have been tested on business registry open data from 10 European countries (Belgium, Cyprus, Greece, Estonia, Finland, France, Latvia, Norway, Romania, United Kingdom).
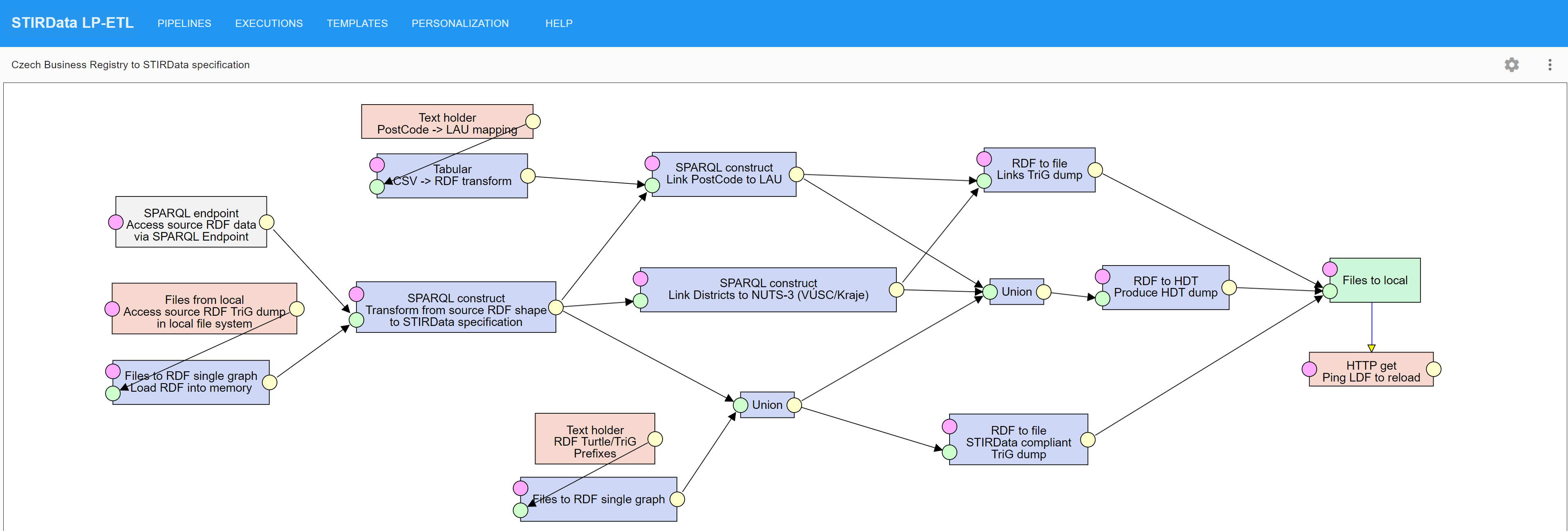
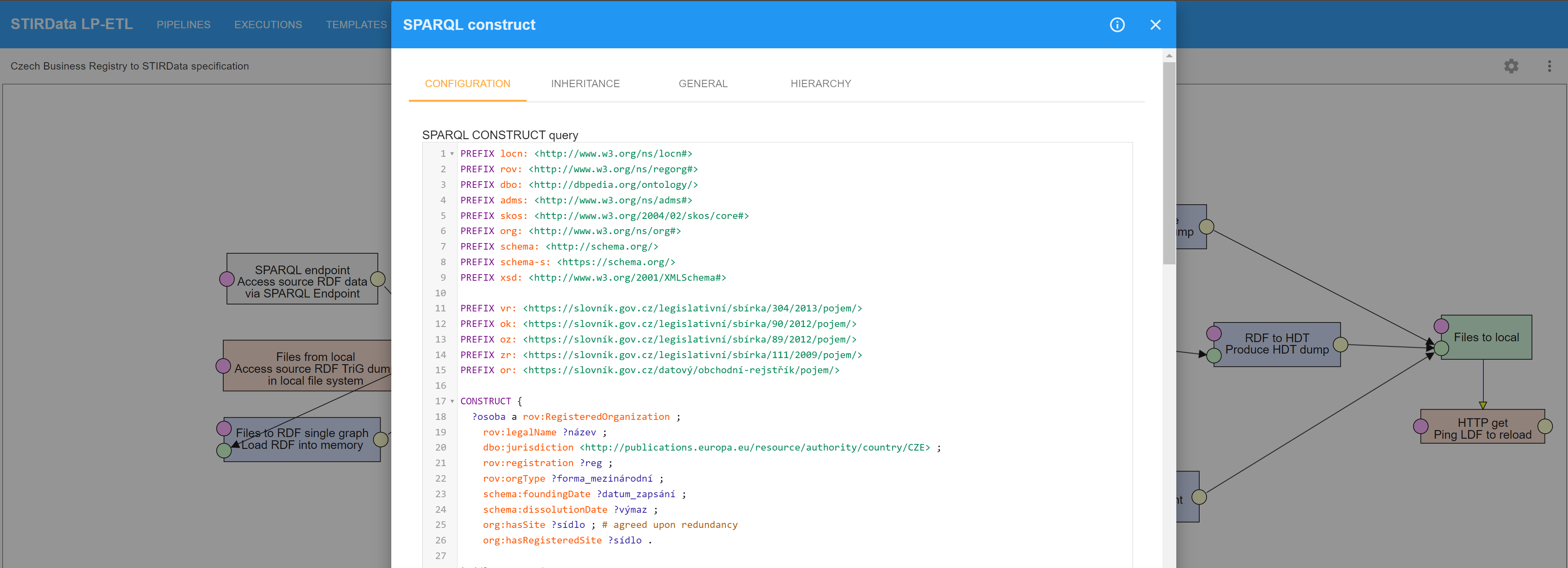
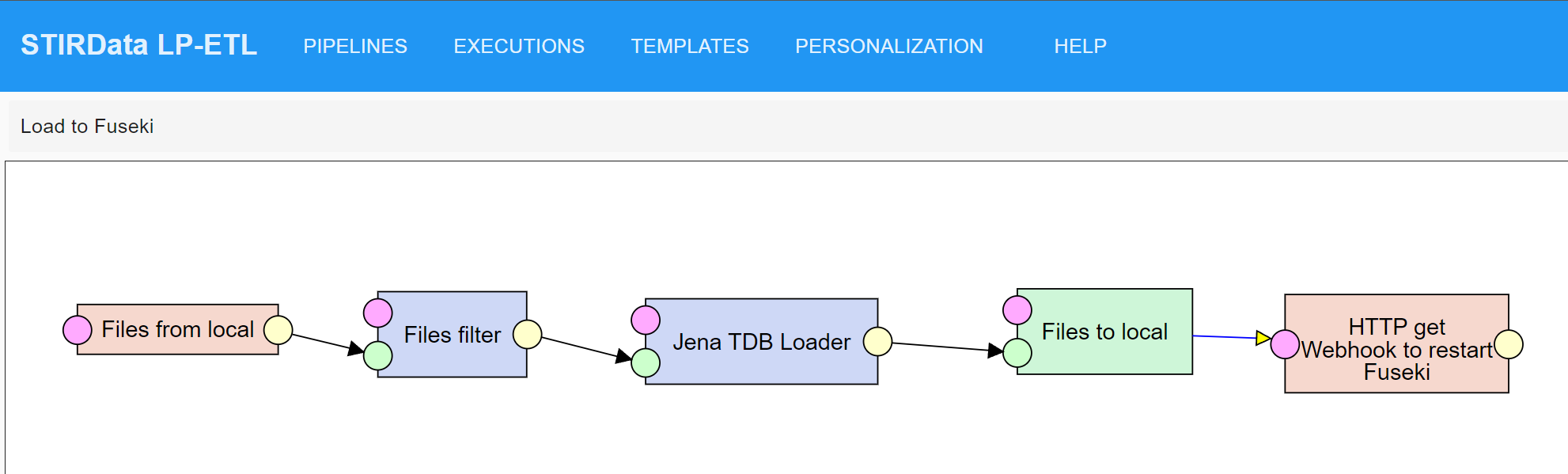
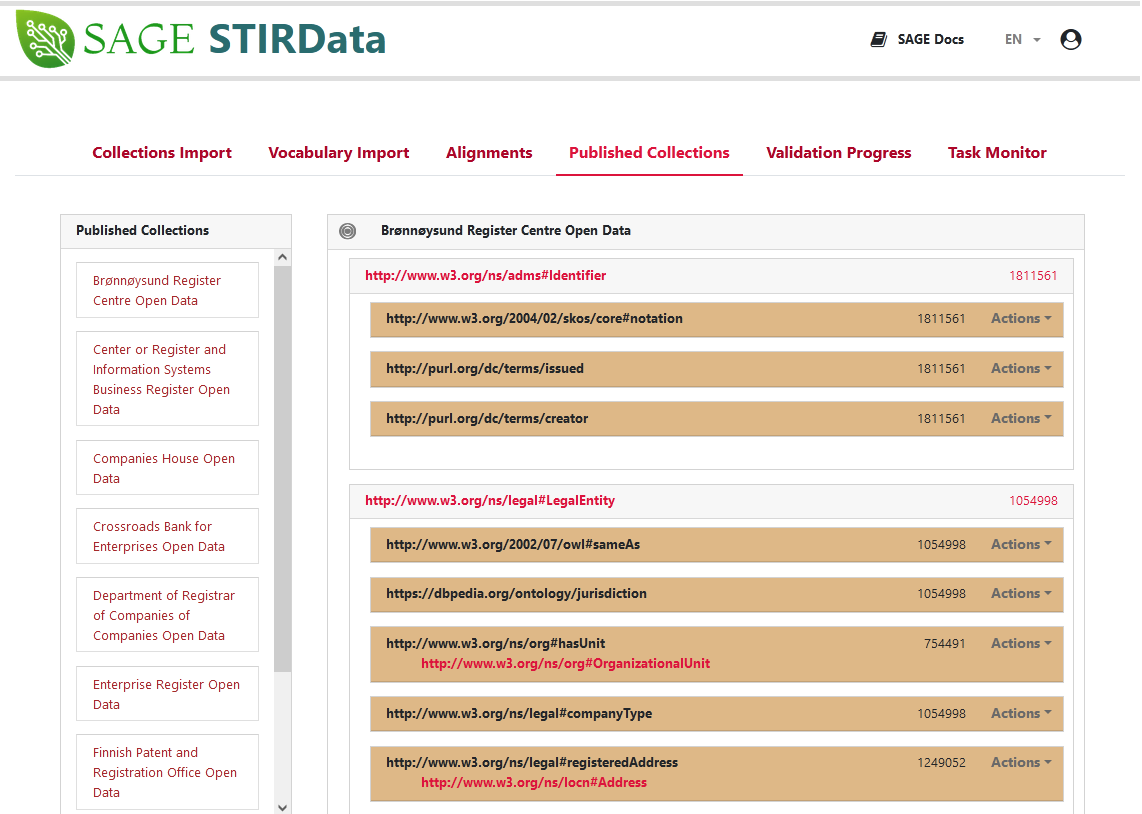
In particular, D2RML mappings have been defined for converting the publicly available business registry data for these countries from their original format to RDF datasets conforming to the STIRData specification.
D2RML mappings have also been defined to generate SKOS versions of the NACE Rev 2 classification, of several local extensions thereof (Nace-Bel 2008, TOL 2008, UK SIC 2007, Norwegian SIC 2007, KAΔ 2008) as well as SKOS versions of the NUTS 2021 and LAU 2021 classifications, including also geospatial data, to which the business data were linked.
These mappings required obtaining data from different sources (national business registries, national open data portals, Eurostat, GISCO) in different ways (direct HTTP download, download upon sign in, download of plain files and compressed files), working on several file formats (CSV, Excel, JSON, XML) and using additional, external REST APIs to enrich original business data based on the address information.
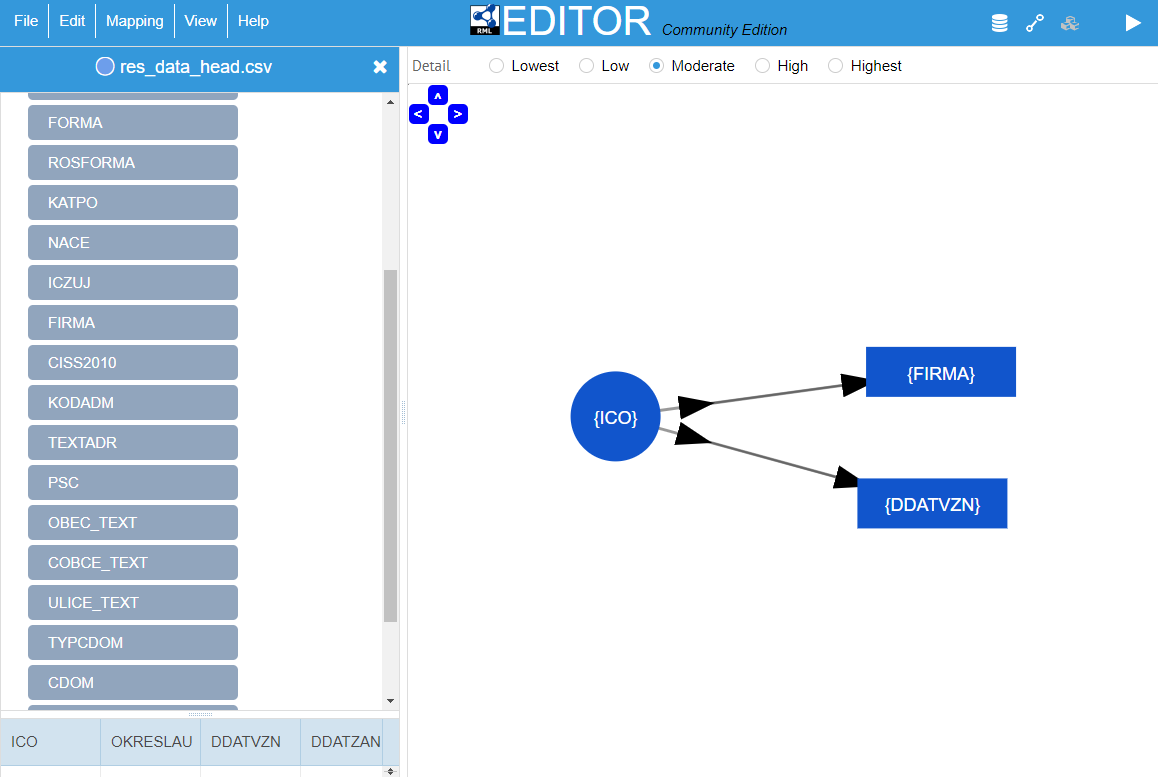
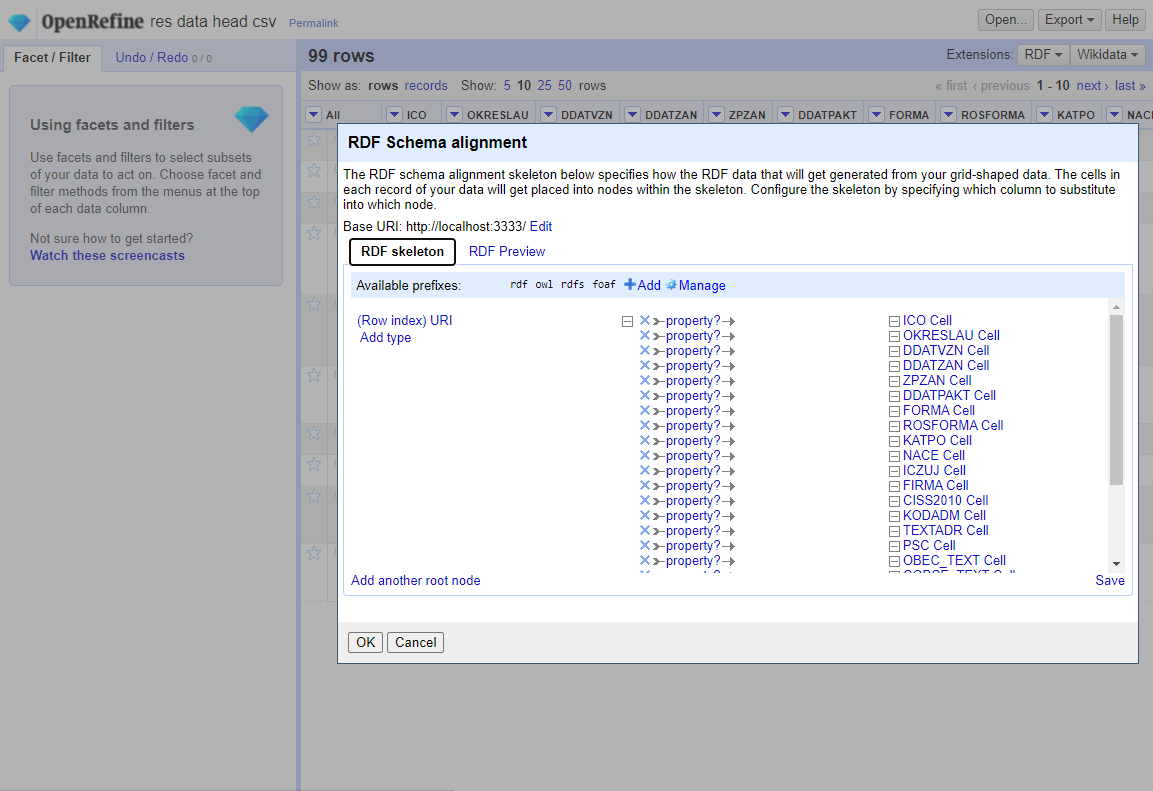
The expressivity of D2RML was sufficient to cover the data transformation needs posed by all the above datasets, without the need for externally obtaining and preprocessing the data.
Complex data transformation needs that are well beyond the scope of a data mapping language, such as resolving country names to ISO 3166 country codes using fuzzy matching, and mapping postcodes to NUTS and LAU regions using information obtained from GIS data were covered within D2RML by calls to external APIs.
Finally, the implementation of the D2RML processor was scalable, and was able to process millions of business register entries, and produce hundreds of thousands of RDF triples per dataset (e.g. about 5 million entries and 140 million triples for the UK Companies House dataset).
The main difficulty in using D2RML is that the user should learn the language in order to be able to express the desired data mapping workflows.
The D2RML specification document provides a detailed discussion of the language.